The goal of this lecture is to introduce a class of models with conditional heteroskedasticity for stationary time series. You will be able to recognize the presence of such heteroskedasticity from graphs or statistical tests and model it.
Objectives
List features of ARCH recognizable from plots.
Diagnose ARCH effects using a statistical test.
Define ARCH(\(p\)) and GARCH(\(p, q\)) models and identify the orders \(p\) and \(q\).
In contrast to the traditional time series analysis that focuses on modeling the conditional first moment, models of autoregressive conditional heteroskedasticity (ARCH) and generalized autoregressive conditional heteroskedasticity (GARCH) specifically take the dependency of the conditional second moment into modeling consideration and accommodate the increasingly important need to explain and model risk and uncertainty in, for example, financial time series.
The ARCH models were introduced in 1982 by Robert Engle to model varying (conditional) variance or volatility of time series. It is often found in economics that the larger values of time series also lead to larger instability (i.e., larger variances), which is termed (conditional) heteroskedasticity. Standard examples for demonstrating ARCH or GARCH effects are time series of stock prices, interest and foreign exchange rates, and even some environmental processes: high-frequency data on wind speed, energy production, air quality, etc. (see examples in Cripps and Dunsmuir 2003; Marinova and McAleer 2003; Taylor and Buizza 2004; Campbell and Diebold 2005). In 2003, Robert F. Engle was awarded 1/2 of the Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel for his work on ARCH models (the other half was awarded to C. Granger, see Section 8.3). Although it is not one of the prizes that Alfred Nobel established in his will in 1895, the Sveriges Riksbank Prize is referred to along with the other Nobel Prizes by the Nobel Foundation.
6.2 Features of ARCH
Since financial data typically have the autocorrelation coefficient close to 1 at lag 1 (e.g., the exchange rate between the US and Canadian dollar hardly changes from today to tomorrow), it is much more interesting and also more practically relevant to model the returns of a financial time series rather than the series itself. Let \(Y_t\) be a time series of stock prices. The returns \(X_t\) measure the relative changes in price and are typically defined as simple returns \[
X_t = \frac{Y_t - Y_{t-1}}{ Y_{t-1} } = \frac{Y_t}{ Y_{t-1} } - 1
\tag{6.1}\] or logarithmic returns \[
X_t = \ln Y_t - \ln Y_{t-1}.
\tag{6.2}\] The two forms are approximately the same, since \[
\begin{split}
\ln Y_t - \ln Y_{t-1} &= \ln \left(\frac{Y_{t}}{Y_{t-1}} \right) \\
&= \ln \left(\frac{Y_{t-1} + Y_{t} - Y_{t-1}}{Y_{t-1}} \right) \\
&= \ln \left(1 + \frac{Y_{t} - Y_{t-1}}{Y_{t-1}} \right) \\
&\approx \frac{ Y_{t} - Y_{t-1}}{ Y_{t -1} }.
\end{split}
\tag{6.3}\] The approximation \(\ln(1+x) \approx x\) works when \(x\) is close to zero, which is true for many real-world financial problems. However, logarithmic returns are often preferred because in many applications their distribution is closer to normal compared to one of simple returns. Also, log returns have infinite support (from \(-\infty\) to \(+\infty\)) compared to simple returns that have a lower bound of \(-1\).
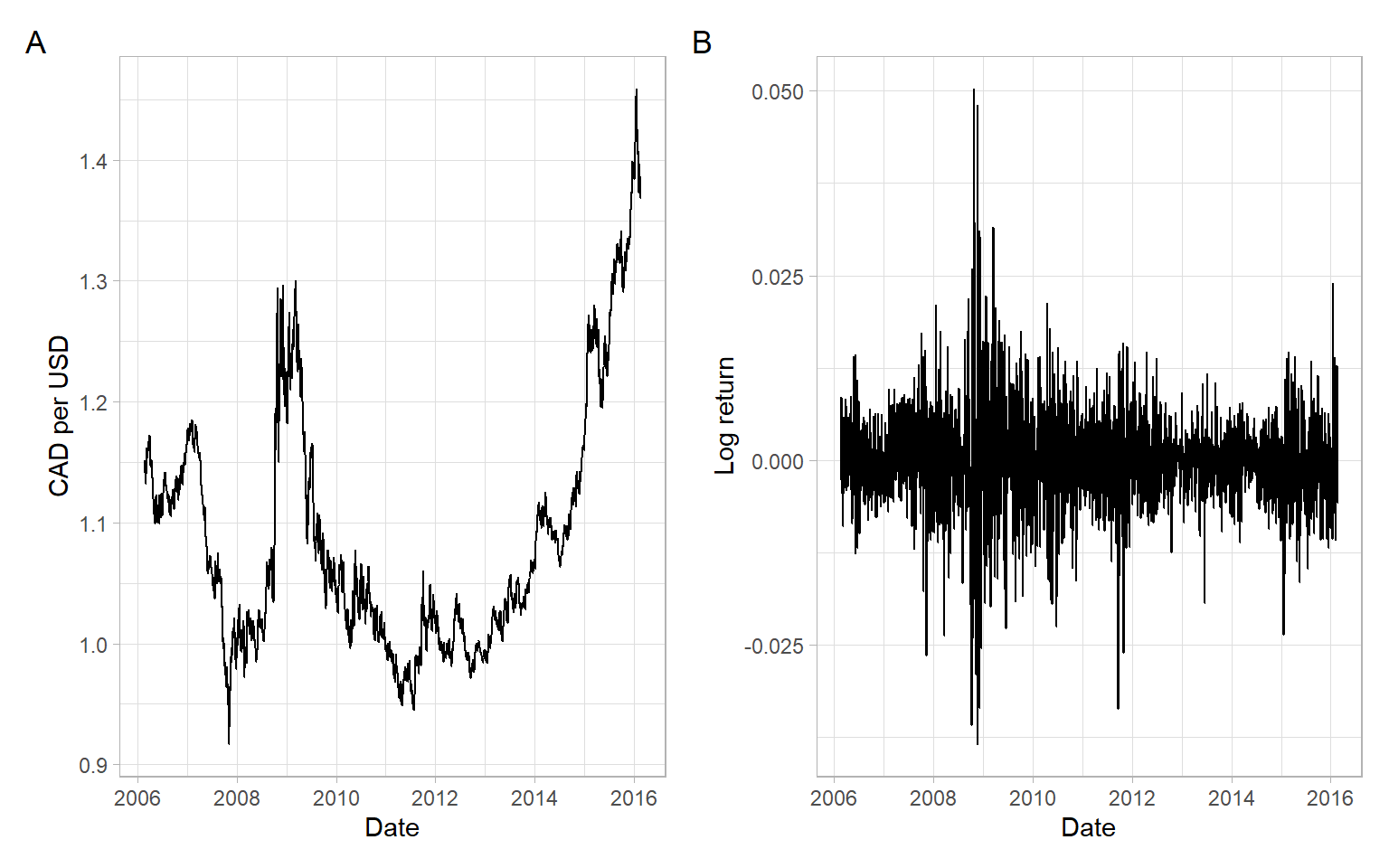
For an example calculation of log returns, see Figure 6.1.
Code
# Load data and calculate log returnsCAD<-readr::read_csv("data/CAD.csv", na ="Bank holiday", skip =11)%>%filter(!is.na(USD))%>%mutate(lnR =c(NA, diff(log(USD))))%>%filter(!is.na(lnR))p1<-ggplot(CAD, aes(x =Date, y =USD))+geom_line()+ylab("CAD per USD")p2<-ggplot(CAD, aes(x =Date, y =lnR))+geom_line()+ylab("Log return")p1+p2+plot_annotation(tag_levels ='A')
Figure 6.1: CAD per USD daily noon exchange rates and log returns, from 2006-02-22 to 2016-02-22 (excluding bank holidays), obtained from Bank of Canada.
Rydberg (2000) summarizes some important stylized features of financial return series, which have been repeatedly observed in all kinds of assets including stock prices, interest rates, and foreign exchange rates:
Heavy tails. The distribution of the returns \(X_t\) has tails heavier than the tails of a normal distribution.
Volatility clustering. Large price changes occur in clusters. Indeed, often large price changes tend to be followed by large price changes, and periods of tranquility alternate with periods of high volatility.
Asymmetry. There is evidence that the distribution of stock returns is slightly negatively skewed. One possible explanation could be that trades react more strongly to negative information than to positive information.
Aggregational Gaussianity. When the sampling frequency decreases, the central limit law sets in and the distribution of the returns over a long period tends toward a normal distribution.
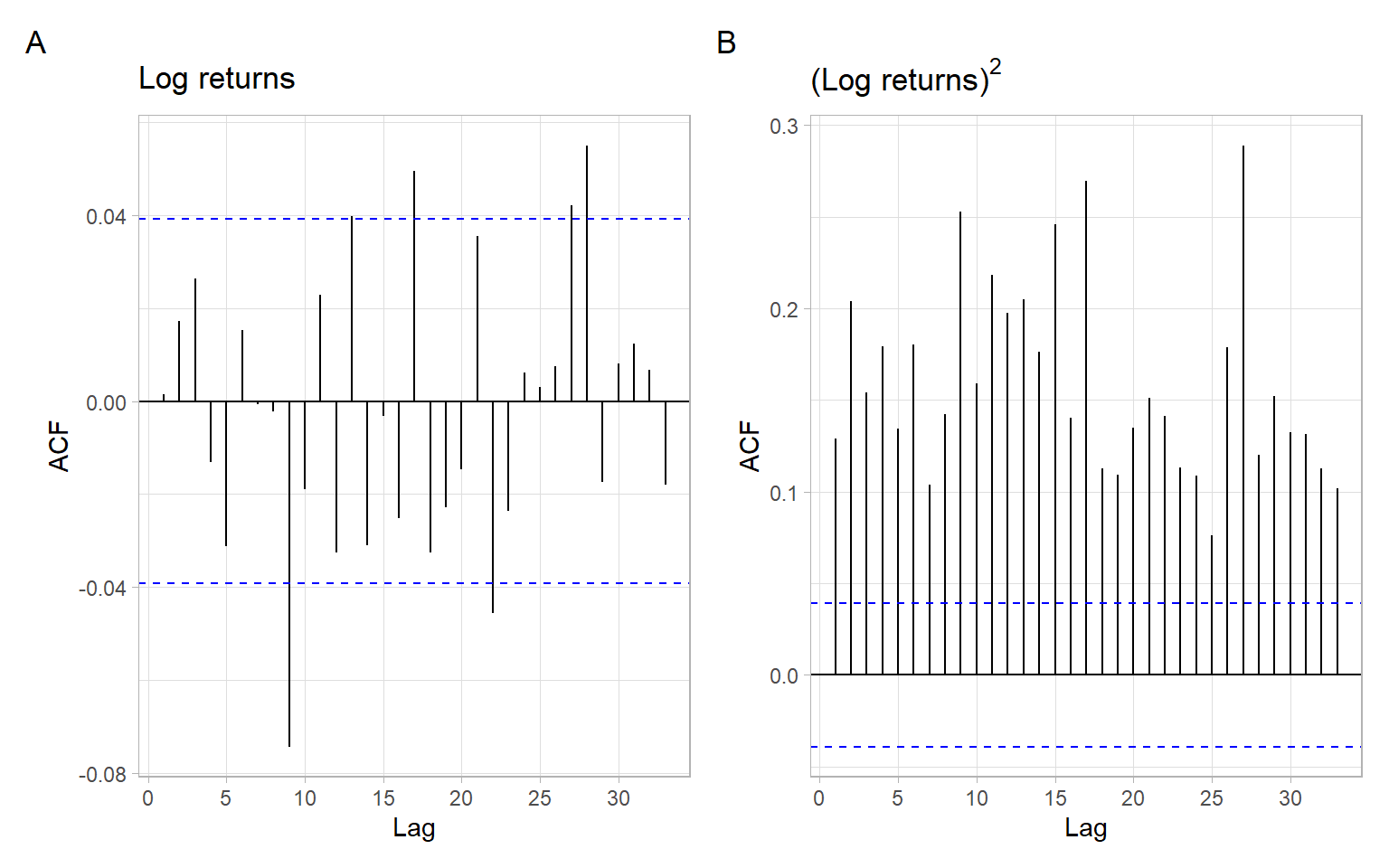
Long-range dependence. The returns themselves hardly show any autocorrelation, which, however, does not mean that they are independent. Both squared returns and absolute returns often exhibit persistent autocorrelations indicating possible long-memory dependence in those series.
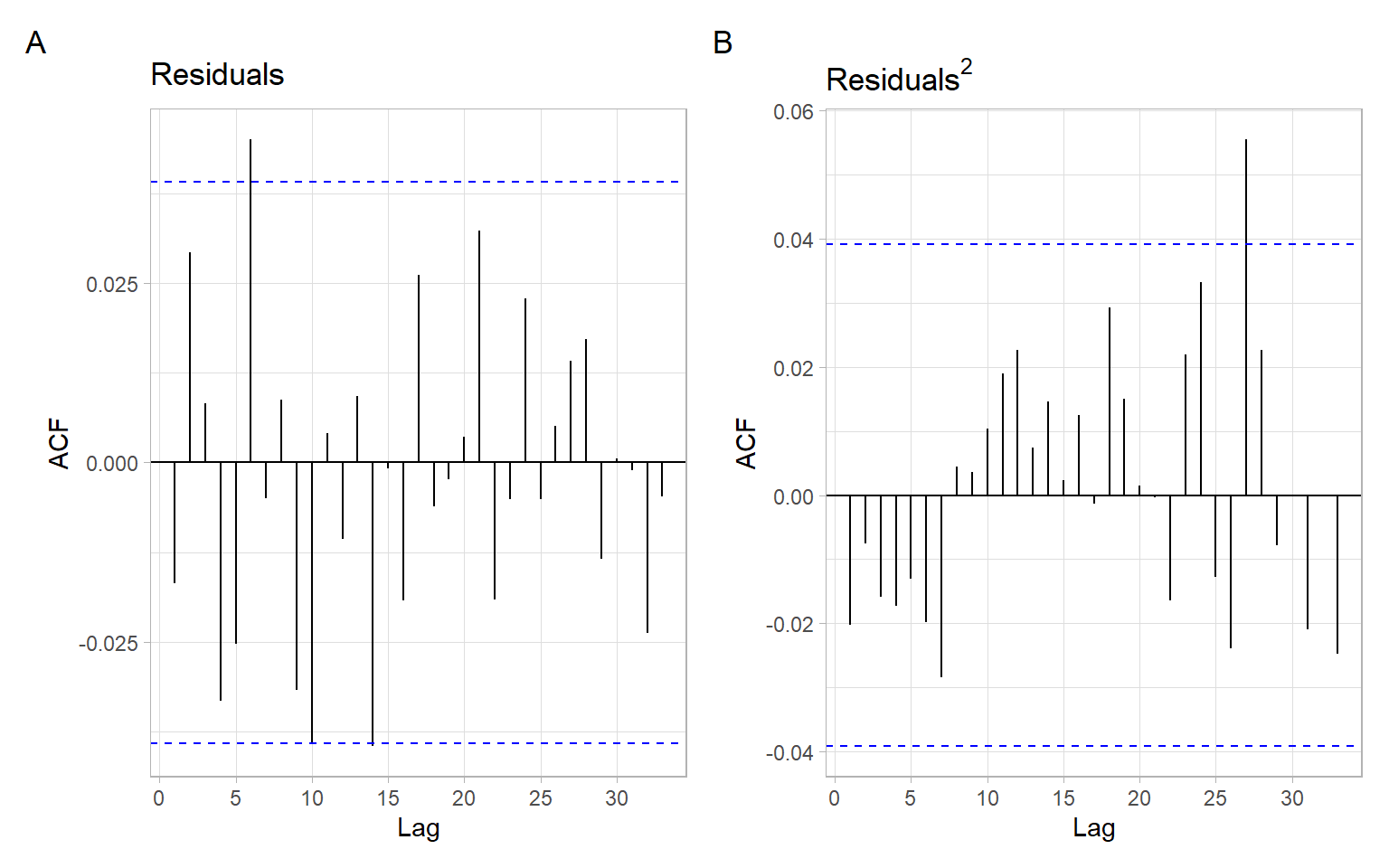
Figure 6.2 is the simplest check for the presence of ARCH effects: when the time series is not autocorrelated but is autocorrelated if squared.
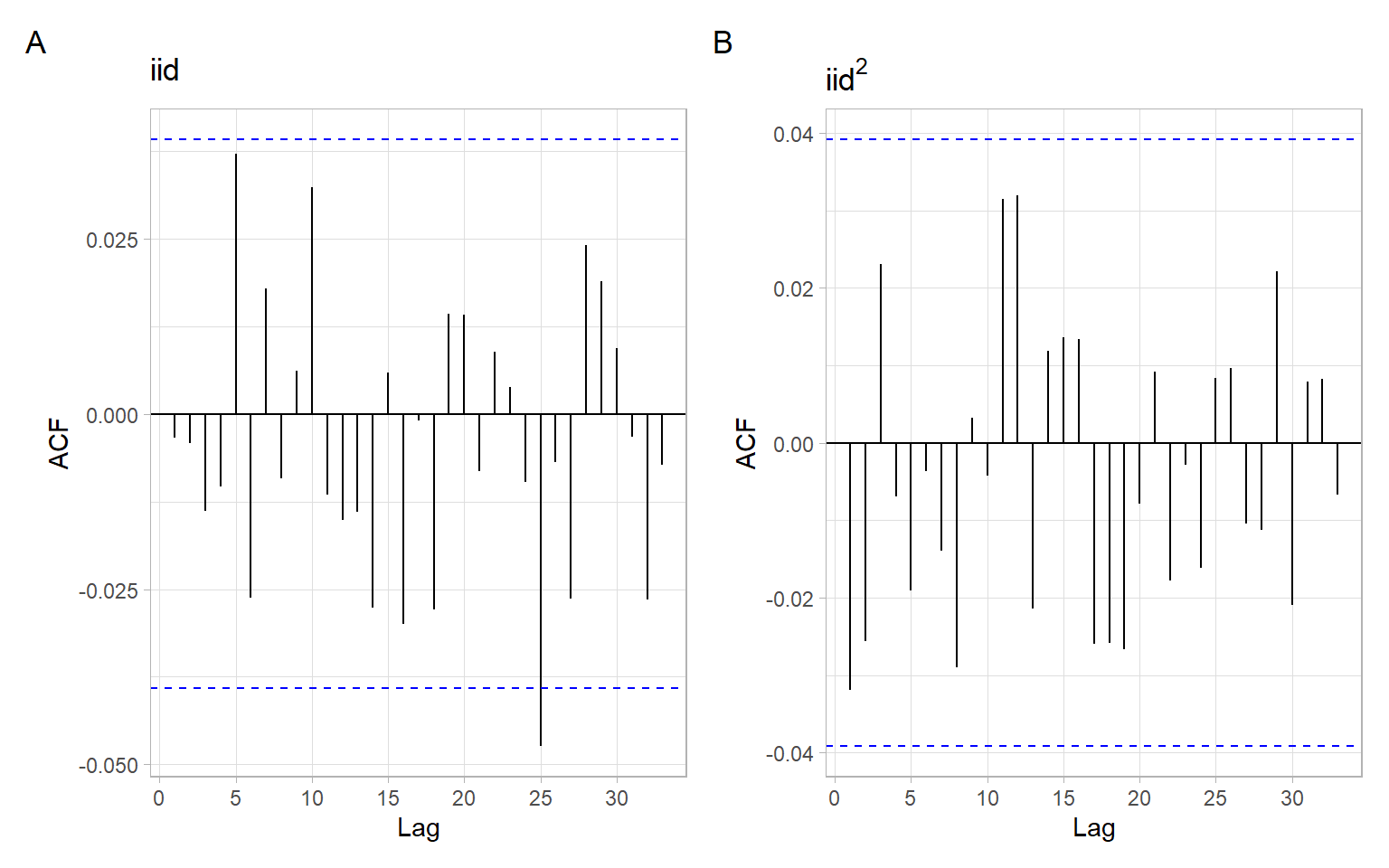
Figure 6.3: ACF of simulated i.i.d. \(N(0,1)\) series.
6.3 Models
Engle (1982) defines an autoregressive conditional heteroskedastic (ARCH) model as \[
\begin{split}
X_{t} &= \sigma_{t} \varepsilon_{t}, \\
\sigma^{2}_{t} &= a_{0} + a_{1} X^{2}_{t-1} + \dots + a_{p} X^{2}_{t-p},
\end{split}
\tag{6.4}\] where \(a_{0} > 0\), \(a_{j} \geqslant 0\), \(\varepsilon_{t} \sim \mathrm{i.i.d.}(0,1)\), and \(\varepsilon_{t}\) is independent of \(X_{t - j}\), where \(j \geqslant 1\). We write \(X_{t} \sim \mathrm{ARCH} (p)\).
We can see that \[
\begin{split}
\mathrm{E} X_{t} & = 0, \\
\mathrm{var} \left( X_{t} | X_{t - 1} , \dots , X_{t - p} \right) &= \sigma^{2}_{t}, \\
\mathrm{cov} \left( X_{t} , X_{k} \right) &= 0 ~~\mathrm{for~all}~~ t \neq k.
\end{split}
\]
Note
Stationary ARCH is white noise.
Thus, in ARCH, the predictive distribution of \(X_{t}\) based on its past is a scale-transform of the distribution of \(\varepsilon_{t}\) with the scaling constant \(\sigma_{t}\) depending on the past of the process.
Bollerslev (1986) introduced a generalized autoregressive conditional heteroskedastic (GARCH) model by replacing the second formula in Equation 6.4 with \[
\begin{split}
\sigma^{2}_{t} &= a_{0} + a_{1} X^{2}_{ t - 1} + \dots + a_{p} X^{2}_{ t - p} + b_{1} \sigma^{2}_{t - 1} + \dots + b_{q} \sigma^{2}_{t - q}\\
&= a_0 + \sum_{i=1}^p a_{i} X^{2}_{ t - i} + \sum_{j=1}^q b_{j} \sigma^{2}_{ t - j},
\end{split}
\tag{6.5}\] where \(a_{0} > 0\), \(a_{i} \geqslant 0\), and \(b_{j} \geqslant 0\). We write \(X_{t} \sim \mathrm{GARCH}(p, q)\).
Notice the similarity between ARMA and GARCH models.
The parameters of ARCH/GARCH models are estimated using the method of conditional maximum likelihood. There exist several tests for ARCH/GARCH effects (e.g., analyzing time series and ACF plots, the Engle’s Lagrange multiplier test).
The approaches to selecting the orders \(p\) and \(q\) for GARCH include:
Visual analysis of ACF and PACF of the squared time series and other residual diagnostics;
Variations of information criteria such as AIC and BIC to account for the number of estimated parameters in the GARCH model (Brooks and Burke 2003);
Using GARCH(1,1) by following Hansen and Lunde (2005);
Using out-of-sample forecasts (comparing alternative model specifications on a testing set).
6.3.1 Lagrange multiplier test
The Lagrange multiplier (LM) test is equivalent to an \(F\)-test for the significance of the least squares regression on squared values: \[
X^{2}_{t} = \alpha_0 + \alpha_1 X^{2}_{t-1} + \dots + \alpha_m X^{2}_{t-m} + e_t,
\tag{6.6}\] where \(e_t\) denotes the error term, \(m\) is a positive integer, \(t = m+1,\dots,T\), and \(T\) is the sample size (length of the time series).
Specifically, the null hypothesis is \[
H_0: \alpha_1 = \dots = \alpha_m = 0.
\] Let the sum of squares total \[
SST = \sum_{t=m+1}^T \left( X_t^2 - \overline{X_t^2} \right) ^2,
\] where \(\overline{X_t^2}\) is the sample mean of \(X_t^2\). The sum of squares of the errors \[
SSE = \sum_{t=m+1}^T \hat{e}_t^2,
\] where \(\hat{e}_t\) is the least-squares residual of the linear regression (Equation 6.6).
Then, the test statistic \[
F = \frac{(SST - SSE)/m}{SSE/(T-2m-1)},
\tag{6.7}\] which is asymptotically distributed under the null hypothesis as a \(\chi^2\) distribution with \(m\) degrees of freedom.
NoteExample: Testing ARCH effects in USD/CAD log returns
We have seen in Figure 6.2 the autocorrelation of squared log returns. Now apply the formal LM test.
The LM test implemented in the function FinTS::ArchTest() detects the presence of ARCH effects (rejects the null hypothesis) when considering 12 lags. In base R, the same results can be obtained by running the \(F\) test as follows:
#> Analysis of Variance Table
#>
#> Response: mat[, 1]
#> Df Sum Sq Mean Sq F value Pr(>F)
#> mat[, -1] 12 5.15e-06 4.29e-07 36.8 <2e-16 ***
#> Residuals 2479 2.89e-05 1.20e-08
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
NoteExample: GARCH model for USD/CAD log returns
Let’s estimate a GARCH(1,1) model for these data, using the conditional ML method. Note that omega in the results below is denoted \(a_0\) in our equations (the intercept in the variance model):
library(fGarch)garch11<-fGarch::garchFit(lnR~garch(1, 1), data =CAD, trace =FALSE)garch11@description<-"---"garch11
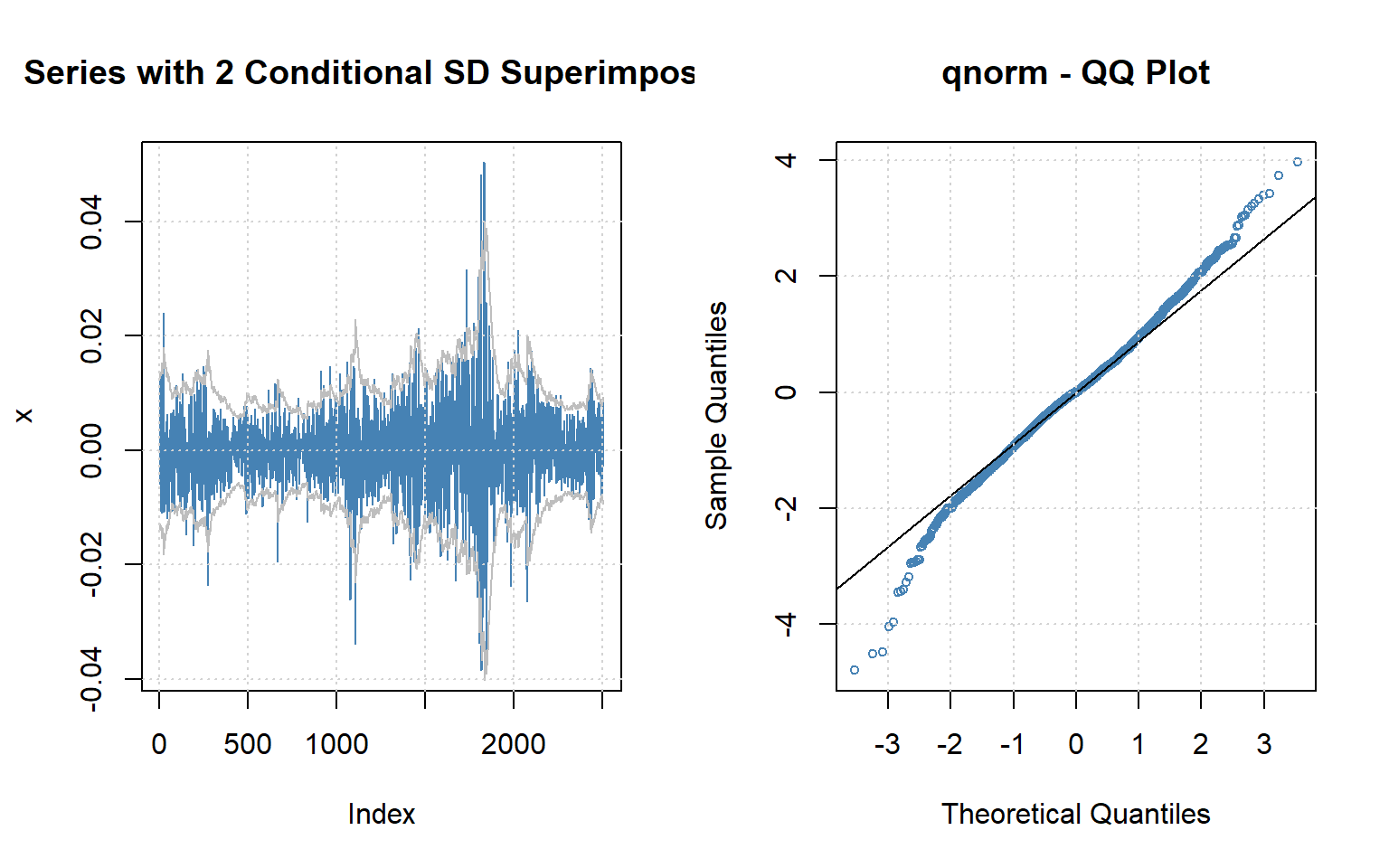
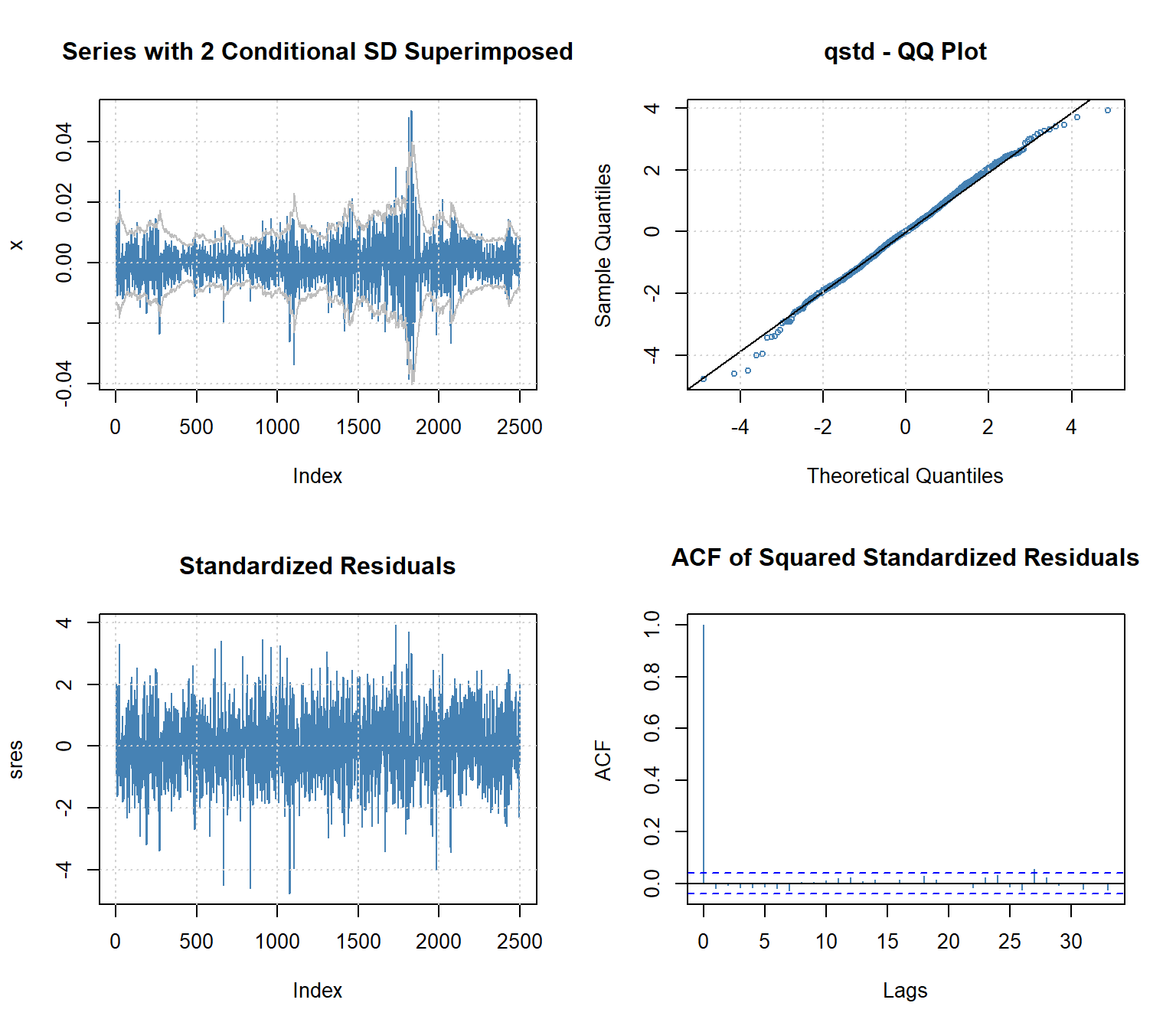
Next, we run diagnostics of the fitted model, i.e., whether the residuals \(\varepsilon_{t}\) are white noise and are normally distributed. The code plot(garch11) generates scatterplots, histograms, Q-Q plots, and ACF plots of the original data and the obtained residuals (Figure 6.4). Of course, the analysis can be performed also with separate commands. For example, see the ACFs of the residuals (Figure 6.5).
Figure 6.5: ACF of residuals from the GARCH(1,1) model for the USD/CAD log returns.
Based on the plots, autocorrelations were effectively removed, but the assumption of normality is violated – Figure 6.4 shows heavy and almost symmetric tails in the distribution of GARCH residuals.
To account for the heavy tails, we change the conditional distribution from normal to the standardized Student \(t\)-distribution (see ?fGarch::std).
garch11t<-fGarch::garchFit(lnR~garch(1, 1), data =CAD, trace =FALSE, cond.dist ="std")garch11t@description<-"---"garch11t
par(mfrow =c(2, 2))plot(garch11t, which =c(3, 13))plot(garch11t, which =c(9, 11))
Figure 6.6: Selected diagnostics of the GARCH(1,1) model with the standardized Student-t distribution for the USD/CAD log returns.
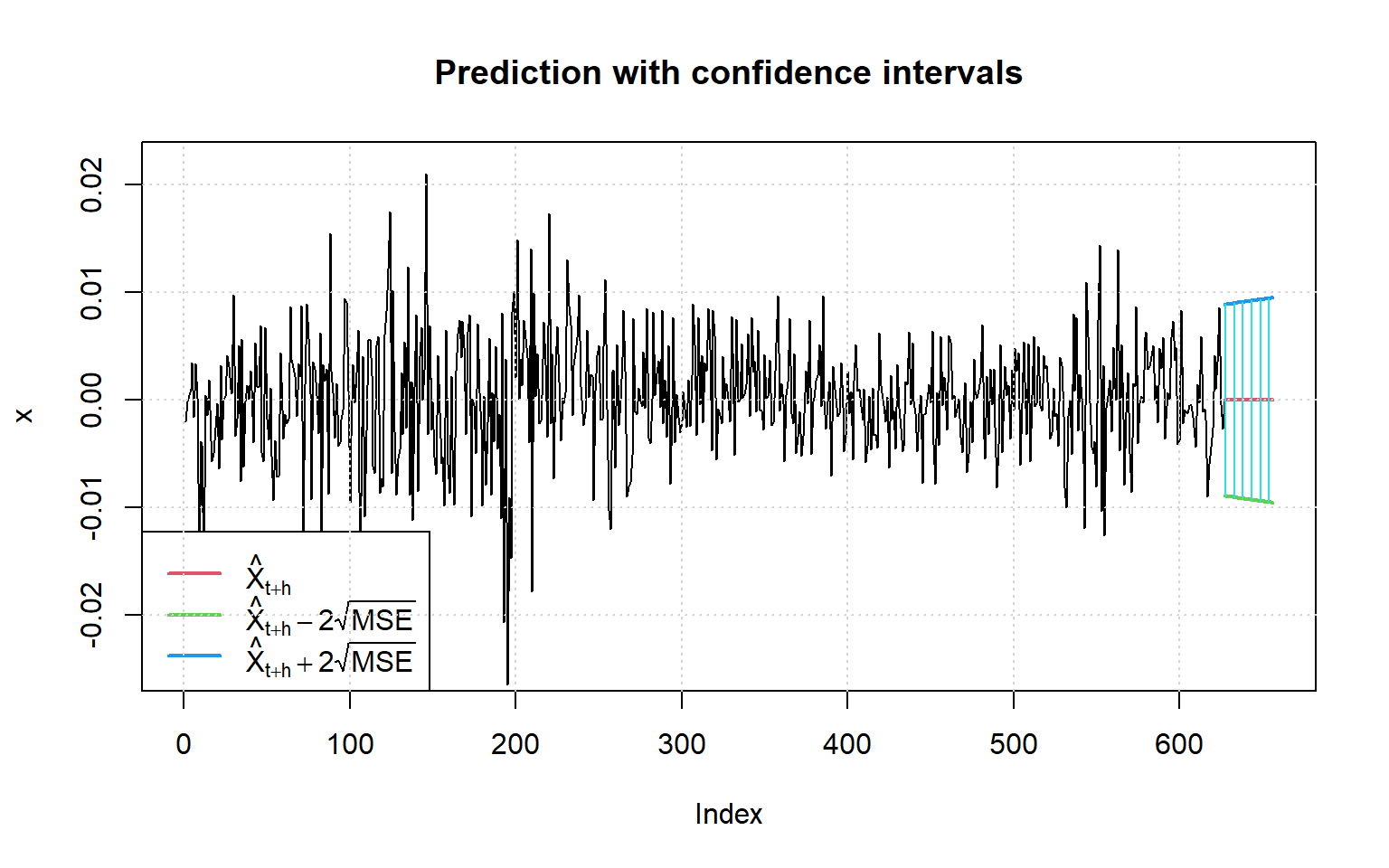
Now we can use the model for predictions (Figure 6.7). Few things to note here:
the model is ‘self-contained’ so we can just specify n.ahead for the number of steps to be predicted;
GARCH models are typically applied to long time series, so the argument nx limits the length of the plotted observed time series (by default only the most recent 25% of observations are plotted);
the argument conf specifies the confidence level, then the conditional distribution from the model is used to compute critical values for the interval forecasts. Alternatively, one can specify the critical values manually with the argument crit_val.
Figure 6.7: Predictions using the GARCH(1,1) model for the USD/CAD log returns.
6.4 Extensions
There was a boom in creating new models by adding new features to GARCH:
IGARCH – integrated GARCH
EGARCH – exponential GARCH
TGARCH – threshold GARCH
QGARCH – quadratic GARCH
GARCH-M – GARCH with heteroskedasticity in mean
NGARCH – nonlinear GARCH
…
MARCH – modified GARCH
STARCH – structural ARCH
…
Thus, these papers had to appear: Hansen and Lunde (2005) and Bollerslev (2009).
6.5 Model building
We have considered the models for conditional heteroskedasticity, and in the example, we estimated the mean just as a constant (intercept mu), however, in a more general case one might need to model and remove trend and cyclical variability along with autocorrelations (recall the methods of smoothing, ARMA, and ARIMA modeling) before exploring the need to model ARCH.
Below are the steps for such a more general case of analysis, adapted from Chapter 3.3 in Tsay (2005):
Specify a mean equation by testing for trend and serial dependence in the data and, if necessary, build a time series model (e.g., an ARMA model) to remove any linear dependence.
Use the residuals of the mean equation to test for ARCH effects.
If the ARCH effects are statistically significant, specify a volatility model and perform a joint estimation of the mean and volatility equations.
Check the fitted model carefully and refine it if necessary.
Note
The joint estimation can be done in R using the function fGarch::garchFit() and specifying, e.g., formula = ~ arma(2, 1) + garch(1, 1).
6.6 Conclusion
Whereas originated in financial analysis, GARCH models are becoming popular in other domains, including environmental science. Note that close alternatives exist, for example, GAMLSS allows modeling different distributional parameters such as mean, scale, skewness, etc.
GARCH effects are tested for and modeled after the mean (i.e., trend) and autocorrelations are removed. Standard model selection techniques can be adapted to specify GARCH models.
R packages offering functions for GARCH modeling include (in alphabetic order): bayesforecast, betategarch, fGarch (used here), garchx, rmgarch, rugarch, tseries, and more (see, for example, CRAN Task Views on Empirical Finance).
Campbell SD, Diebold FX (2005) Weather forecasting for weather derivatives. Journal of the American Statistical Association 100:6–16. https://doi.org/10.1198/016214504000001051
Engle RF (1982) Autoregressive conditional heteroscedasticity with estimates of the variance of UnitedKingdom inflation. Econometrica 50:987–1007. https://doi.org/10.2307/1912773
Hansen PR, Lunde A (2005) A comparison of volatility models: Does anything beat a GARCH(1, 1)? Journal of Applied Econometrics 20:873–889. https://doi.org/10.1002/jae.800
Marinova D, McAleer M (2003) Modelling trends and volatility in ecological patents in the USA. Environmental Modelling & Software 18:195–203. https://doi.org/10.1016/S1364-8152(02)00079-8
Rydberg TH (2000) Realistic statistical modelling of financial data. International Statistical Review 68:233–258. https://doi.org/10.2307/1403412
Taylor JW, Buizza R (2004) A comparison of temperature density forecasts from GARCH and atmospheric models. Journal of Forecasting 23:337–355. https://doi.org/10.1002/for.917
Tsay RS (2005) Analysis of financial time series, 2nd edn. John Wiley & Sons, Hoboken, NJ, USA